Bioinformatics
BLAST
BLAST can be very time consuming to run and I needed to get people to use the HPC resources in the best possible way. So I did some experiments.
This is a brief description of a couple of experiments that I (mjv08) have tried out using blast in order to determine the best way in which to run it.
NOTE: It is worth mentioning that other jobs from other people were running at the same time, so there may be odd things happening that would average out if I ran more tests.
Okay, so you have a fasta file you wish to blast. The file I had was supplied by Russ (rom) and contained 18788 sequences in a fasta file. He wanted to run the default settings for blast using blast2go. These settings using blast+ on the command line are;
The first thing I have done is to take a single sequence (length=998) and used blastx against the ncbi nr database. This was run on a 32core AMD node and increased the number of threads that blast uses. The graph below shows the results of this, with the time taken and vmem used to complete the job.

This shows that increasing the number of threads adds around 2-3GB vmem per thread after the initial ~10GB vmem used for 1 thread. There is an oddity when using 2 and 3 threads where the vmem usage seems to decrease.
The time taken to complete the blast does not decrease once the maximum number of cores available on the node is reached, in this case it is 32 cores and the time taken is 20seconds.
This is further confirmed when looking at the same experiment running on the 8 core intel nodes.
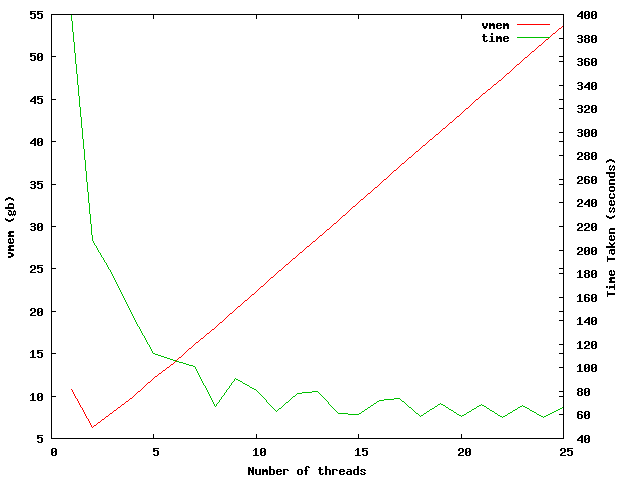
As you can see, the time taken drops to around ~60 seconds after reaching 8 threads. The increase in threads does nothing to improve performance, only increasing the amount of memory required.
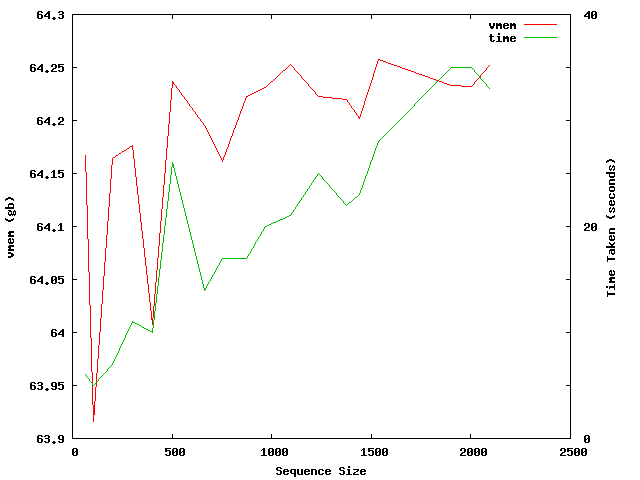
In this next graph I test the time taken to run various sequences of different sizes using the 32core AMD node with 32 threads.
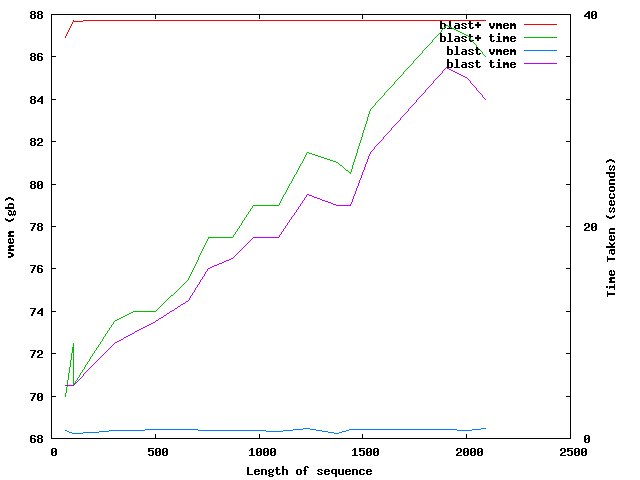
This does show that the sequence size effects the time take to complete, however has very little impact on the amount of vmem required to complete the job.
Install Fastx
export GTEXTUTILS_CFLAGS=-I/cm/shared/apps/libgtextutils/0.7/include/gtextutils
export GTEXTUTILS_LIBS='-L/cm/shared/apps/libgtextutils/0.7/lib -lgtextutils'
./configure --prefix=/cm/shared/apps/fastx-toolkit/0.0.14
make -j4